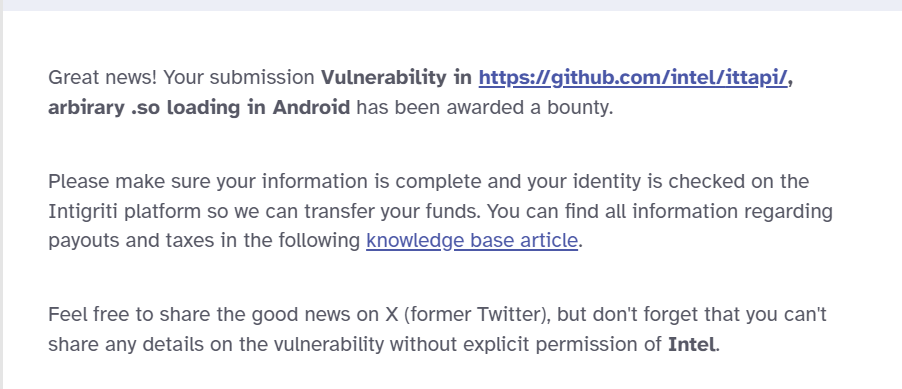
Intel® Instrumentation and Tracing Technology (ITT) is a profiling API that developers use to analyze performance. The ITT library is available for many platforms. It used by many Android applications, either directly, or indirectly (e.g: via precompiled OpenCV library for Android officially downloaded from OpenCV website).
A bug was found that allows ITT to load arbitrary shared library. This shared library can do anything (executing arbitrary code, exfiltrating data, etc). Fortunately the exploitation is not that easy (requires adb access either via PC or Shizuku app, so remote exploitation should not be possible). POC is available on my github, but read on to understand this bug.
OpenCV copies all ITT API files verbatim to their 3rdparty/ittnotify directory. ITT is always built for Android platform (can’t be disabled via CMake config):
OCV_OPTION(BUILD_ITT "Build Intel ITT from source"
(NOT MINGW OR OPENCV_FORCE_3RDPARTY_BUILD)
IF (X86_64 OR X86 OR ARM OR AARCH64 OR PPC64 OR PPC64LE) AND NOT WINRT AND NOT APPLE_FRAMEWORK
)
Any Android application using OpenCV up until 4.10 is affected, 4.11 and later are safe. There is no warning about this CVE in OpenCV because they were released before this CVE was published and they have accidentally fixed the bug (see this) because someone wants to support OpenBSD (“3rdparty/ittnotify had not been updated until 9 years. To support OpenBSD, I suggest to update to latest release version v3.25.4“)
I recently helped a company recover their data from the Akira ransomware without paying the ransom. I’m sharing how I did it, along with the full source code.
Update: since this article was written, a new version of Akira ransomware has appeared that can’t be decrypted with this method
To clarify, multiple ransomware variants have been named Akira over the years, and several versions are currently circulating. The variant I encountered has been active from late 2023 to the present (the company was breached this year).
There was an earlier version (before mid-2023) that contained a bug, allowing Avast to create a decryptor. However, once this was published, the attackers updated their encryption. I expect they will change their encryption again after I publish this.
It is listed under the version: Linux V3. The sample can be found on virus.exchange (just paste the hash to search).
Note that the ransom message and the private/public keys will differ.
We do this not because it is easy, but because we thought it would be easy
I usually decline requests to assist with ransomware cases. However, when my friend showed me this particular case, a quick check made me think it was solvable.
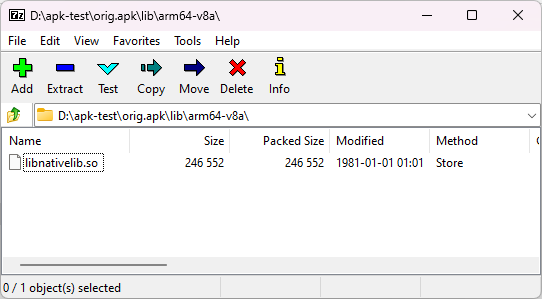
If we installed an Android APK and we have a root access, we can modify the .so (native) filesof that app without altering the signature. This is true even if extractNativeLibs is set to false in AndroidManifest.xml. We can also patch the AOT compiled file (ODEX/VDEX) without changing the package signature, but that’s another story, I am just going to focus on the native code.
native libraries are stored uncompressed and page aligned
As a note: this is not a vulnerability, it requires root access. This method was discussed in the Mystique exploit presentation (2022). I just want to show that this is useful for pentest purpose, with an extra tip of how to write binary patch in C.
Background
I was doing a pentest on an Android app with a complex RASP. There are many challenges:
If I unpack the APK file and repack it, it can detect the signature change
If I use Frida, it can detect Frida in memory, even when I change the name using fridare
It can detect Zygisk, so all injection methods that use Zygisk are detected
It can detect hooks on any function, not just PLT. It seems that it is done by scanning the prologue of functions to see if it jumps to a location outside the binary; the app developer needs to call this check manually (this is quite an expensive operation), which is usually done before it performs some critical scenario.
The RASP uses a native library, which is obfuscated
Given enough time, I am sure it is possible to trace and patch everything, but we are time-limited, and I was only asked to check a specific functionality.
When looking at that particular functionality, I can see that it is implemented natively in a non-obfuscated library. In this specific case, If I can patch the native code without altering the signature, I don’t need to deal with all the anti-frida, anti-hook, etc.
I want to make a WhatsApp message backup from a non-rooted Android 12 Phone. A few years ago, I used Whatsapp-Chat-Exporter to convert the backup to HTML, but first, I had to extract the database from the phone.
The method pointed out by Whatsapp-Chat-Exporter to extract from non-root has remained the same for many years: downgrade to an old version of WhatsApp that allows backup, then create an Android backup that contains the WhatsApp database.
This doesn’t work for WhatsApp for Business because there was no version that allowed backup. Depending on your use case, you might be able to move WhatsApp to a new device that can be rooted and then extract the files there (very easy when you have root access).
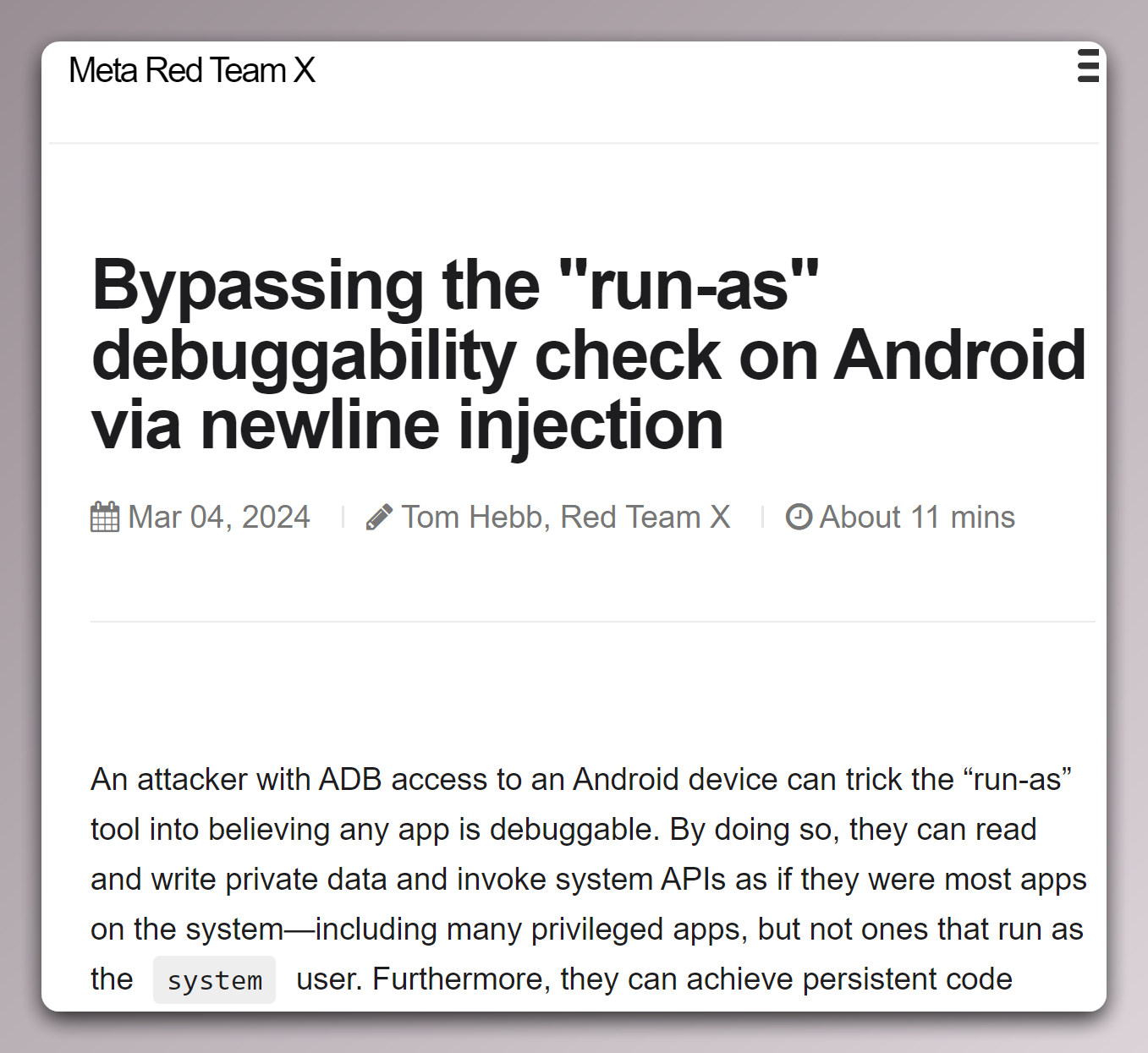
When looking at the new Zygote Bug by Meta Red Team X (CVE-2024-31317), I thought it could be used to perform backup extraction, but then I saw the previous entry on that blog (CVE-2024-0044), which is much easier to use (but only works in Android 12 and 13 that has not received Marh 2024 security update).
CVE-2023-0044
This exploit can work for any non-system app, not just for extracting data from WhatsApp/WhatsApp business. For an expert, the explanation for the exploit is very obvious. I am writing here for end users or beginners who need a step-by-step guide to extracting their WA database.
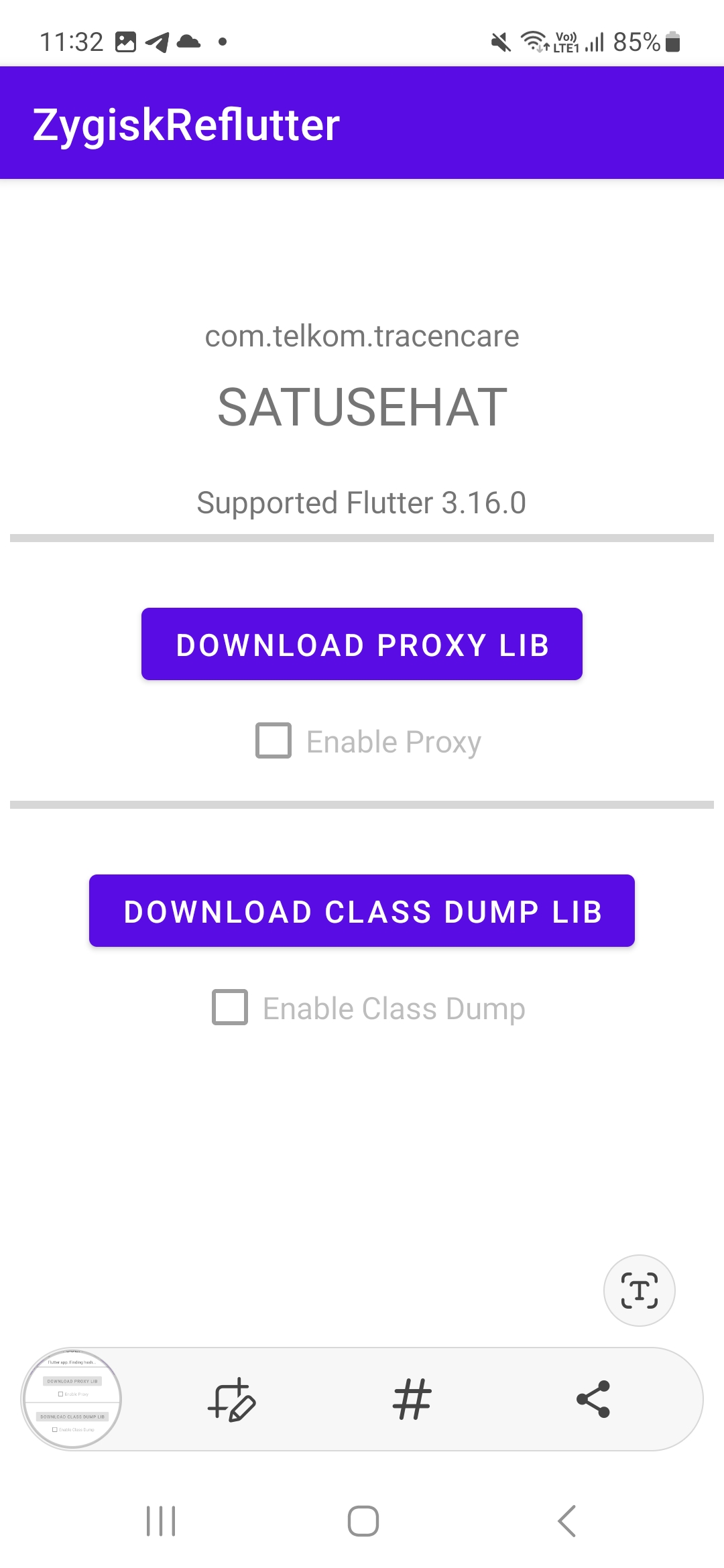
I developed a Zygisk module for rooted Android phones with Magisk (and Zygisk enabled). This module allows you to “reFlutter” your Flutter App at runtime, simplifying the testing and reverse engineering processes.
If you don’t want to read the detail, the release is available at:
This is a guide to extract the boot image from a cheap Android tablet based on Allwinner A133 using U-Boot (accessed via UART). The original firmware was not found on the internet. With the boot image and Magisk, you can root your Android tablet to make it more useful.
Pritom P7 is a very cheap Android tablet. I bought it for 33 USD from AliExpress, but it can be found for as low as 27 USD. This is a Google GMS-certified device (it passes Play Integrity, no malware was found when I received it), and it uses 32-bit Android Go. I am only using this to test some 32-bit Android app compatibility.
I bought it for 32.75 USD
They may have several variants of this model with different specifications. Mine is: Alwinner A133, 1.5GB RAM (advertised as 2GB, and shown as 2GB in the Android info), 32 GB ROM, only 2.4 GHz WIFI, no GPS.
Unlockable Bootloader
Luckily, we are allowed to unlock the bootloader of this device using the developer menu, adb reboot bootloader then using fastboot oem unlock. Some cheap Android devices don’t allow unlocking (for example, the ones that are based on recent Unisoc SOC).
I can allow bootloader unlock using the OEM Unlocking option
The product ID of my tablet is P7_EEA (Android 11) with kernel version Linux localhost 5.4.180-svn33409-ab20220924-092422 #28 SMP PREEMPT Sun Aug 20 19:13:45 CST 2023 armv8l. The build number is PRITOM_P7_EEA_20230820.
I did not find any Android exploit for this device, and I also didn’t find any backdoors. From my experience, some of these cheap Android devices have hidden su backdoors. Unable to find an exploit, I gave up trying to extract boot image from user space.
With some SOC, you can easily read/dump/extract the flash using PC software. I didn’t find any software for this Allwinner chip. An example of a SOC that allows flash reading is Unisoc (formerly Spreadtrum), but on the other hand, the bootloader on phones and tablets with the latest SOCs from Unisoc (that I know of) is not unlockable.
UART
Fortunately, this device is easy to open, and a UART pin is on the top left near the camera.
A friend gave me an Anbernic RG35XX to hack. This is a retro gaming device (it just means that it is designed to emulate old consoles). It comes with two OS: Stock OS and Garlic OS. Stock OS is closed source, and Garlic OS is open source, except for the kernel part (all are closed source). You can switch from one OS to another via a menu.
Stock OS starting my custom binary.
In my opinion, the stock OS is fast and quite user-friendly but is not customizable, although many people like Garlic OS more because it can emulate more systems.
Kernel part
Anbernic won’t release the source for ATM7039S, and no datasheet is found for this SOC. The stock RG35XX OS uses a slightly different kernel compared to the Garlic OS.
There is no serial port accessible and no debug interface available, so trying to hack the kernel will be a painful experience.
Stock RG35XX boot sequence
The kernel is stored as a uImage file on the first partition (FAT32). The built-in bootloader (u-boot) will boot load this file, and it will mount ramdisk.img. Inside ramdisk.img , we can find: /init, /init.rc, loadapp.sh. The kernel will start /init, which is based on Android init (it uses bionic libc). /init will load /init.rc, and on the last lines, it contains instructions to start loadapp.sh
service loadapp /system/bin/logwrapper /loadapp.sh
class core
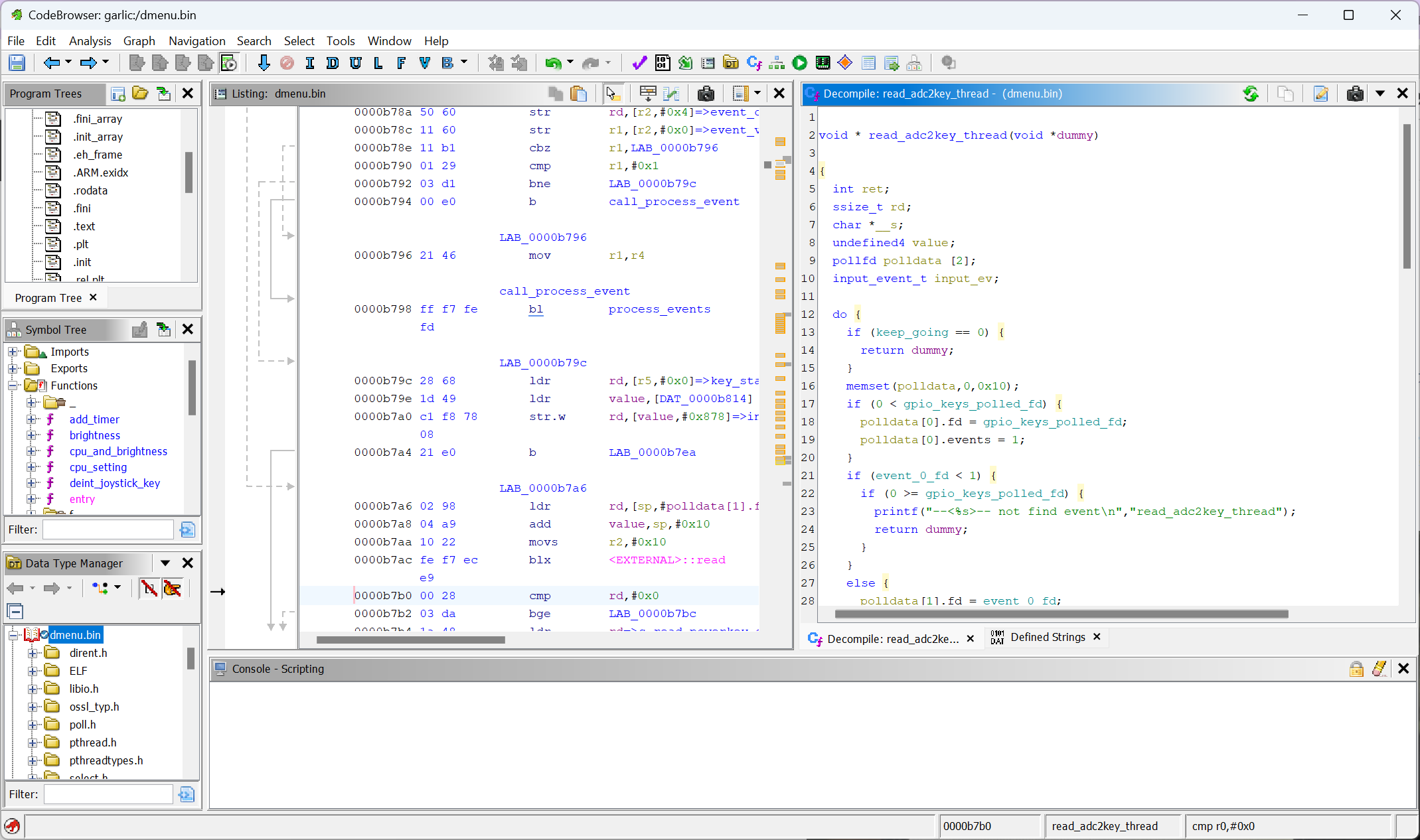
loadapp.sh will load /system/dmenu/dmenu_ln. The dmenu_ln can be found on the second partition (ext4), and this is just a shell script that will start /mnt/vendor/bin/dmenu.bin that can also be found on the second partition.
dmenu.bin is the main shell for the OS. This is written in C using SDL1.2, but it uses custom input handling instead of using SDL_WaitEvent.
Custom Input Handling
Some people swear that the input handling in the Stock RG35XX OS is faster than the other alternative OS. I can’t feel it, but the Stock OS does process input events manually.
To reverse engineer how it works, I use Ghidra. Since this is not security-related software, there is no protection or obfuscation so the code can be decompiled quite cleanly.
Reverse engineering
It starts by opening /dev/input/ to find a device that has a name: gpio-keys-polled (this name is obtained using ioctl call with request EVIOCGNAME). Then, it will start a thread (using pthread) to poll this device. The power button is a separate device from all other buttons, and the reset button (under the power button) is hardwired to reset the console.
Emulator modification
Inside appres/bin/game on the second partition, we can see several binaries for each emulator. All of them have been modified by Anbernic:
They use custom error handling
The menu button is set to display the menu (so all emulators have the same interface)
Added Video filter effect (such as dot-matrix) implemented in C (not using GPU)
Compiling for RG35XX stock OS
Usually, we will need an SDK to compile an app, but since we know the target architecture, calling convention, and the libraries used, we can work around this problem. To compile a simple SDL app that will run on the Stock OS, we will need a compiler, header files, and some libraries.
For the compiler, download Linaro toolchain 4.7 (closest to existing binaries on the system) from here (choose gnueabihf):
For the headers, download the latest SDL1.2 and use the default SDL config. And for the libraries, we can use files from /lib on the second partition. Remove libc.so and libm.so, these two are bionic files and will cause errors. Then, add files from usr/local/lib/arm-linux-gnueabihf (also from the second partition).
Then, you should be able just to compile everything manually.
Outputs to stdout/stderr will not be visible, so use dup2 to redirect these to files.
Small Demo App
In this repository, you can see my small demo app. I included all the libraries to make it easy for anyone to start (please change CC path in Makefile to your installation directory).
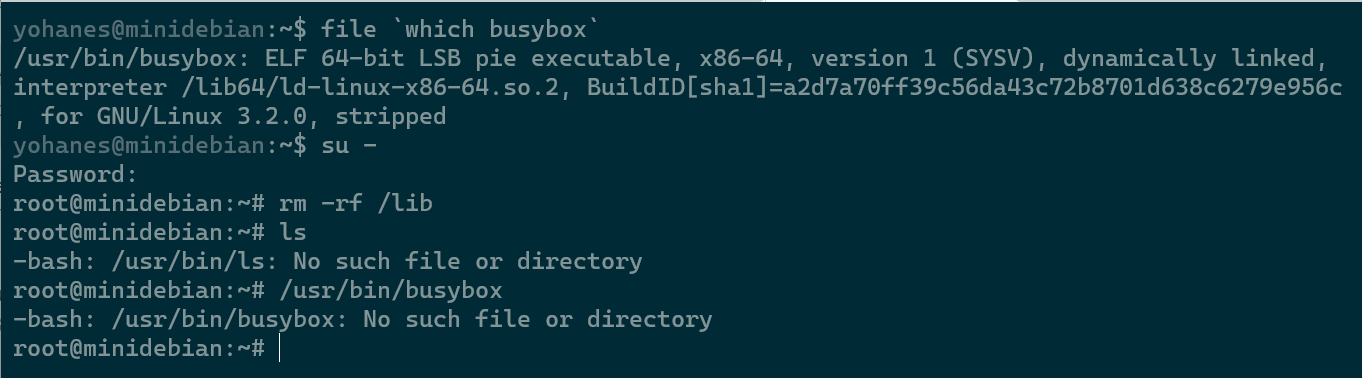
Let’s first not talk about why this can happen, but deleting /lib, /usr/lib, or some other essential runtime files happens quite a lot (as you can see: here, here, here,and here). In this post, I will only discuss what happens when you delete /lib on Linux and how to recover from that.
The easy solution for everything is to replace the missing files, but this can be difficult if /lib is deleted because we won’t have ld-linux, which is needed to run any dynamic executable. When you deleted /lib, all non-static executable (such as ls, cat, etc, will output):
No such file or directory
You will also be unable to open any new connection using ssh, or open a new tmux window/pane if you are using tmux. So you can only rely on your current shell built in, and some static executables that you have on the system.
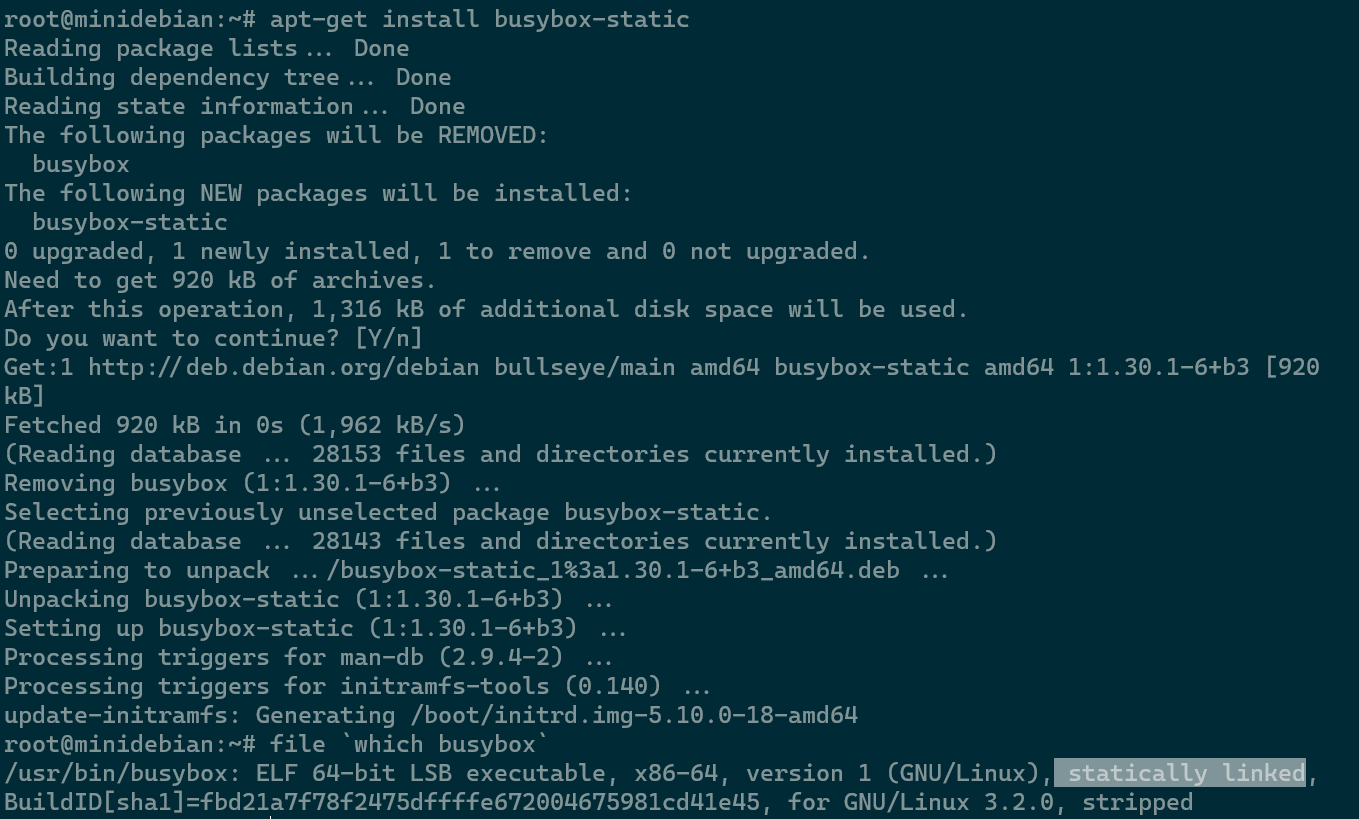
If you have a static busybox installed, then it can be your rescue. You can use wget from busybox to download libraries from a clean system. For your information: Debian has busybox installed by default, but the default is not the static version.
Minimal Debian install
If you are worried that this kind of problem might happen to you in the future: Install the static version of the busybox binary, and confirm that it is the correct version.
It is not easy to reverse engineer a release version of a flutter app because the tooling is not available and the flutter engine itself changes rapidly. As of now, if you are lucky, you can dump the classes and method names of a flutter app using darter or Doldrums if the app was built with a specific version of Flutter SDK.
If you are extremely lucky, which is what happened to me the first time I needed to test a Flutter App: you don’t even need to reverse engineer the app. If the app is very simple and uses a simple HTTPS connection, you can test all the functionalities using intercepting proxies such as Burp or Zed Attack Proxy. The app that I just tested uses an extra layer of encryption on top of HTTPS, and that’s the reason that I need to do actual reverse engineering.
In this post, I will only give examples for the Android platform, but everything written here is generic and applicable to other platforms. The TLDR is: instead of updating or creating a snapshot parser, we just recompile the flutter engine and replace it in the app that we targeted.
Flutter compiled app
Currently several articles and repositories that I found regarding Flutter reverse engineering are:
Reverse engineering Flutter for Android (explains the basic of snapshot format, introduces, Doldrums, as of this writing only supports snapshot version 8ee4ef7a67df9845fba331734198a953)
Reverse engineering Flutter apps (Part 1) a very good article explaining Dart internals, unfortunately, no code is provided and part 2 is not yet available as of this writing
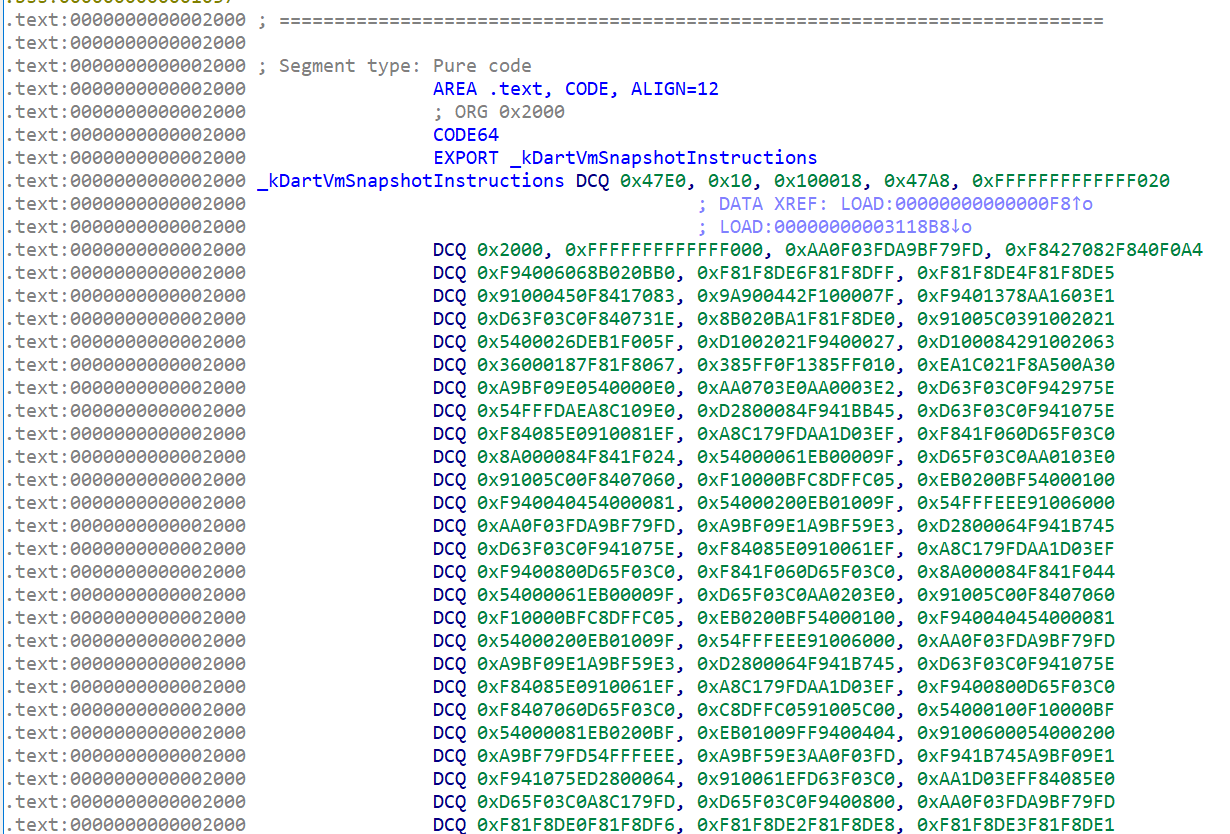
The main code consists of two libraries libflutter.so (the flutter engine) and libapp.so (your code). You may wonder: what actually happens if you try to open a libapp.so (Dart code that is AOT compiled) using a standard disassembler. It’s just native code, right? If you use IDA, initially, you will only see this bunch of bytes.
If you use other tools, such as binary ninja which will try to do some linear sweep, you can see a lot of methods. All of them are unnamed, and there are no string references that you can find. There is also no reference to external functions (either libc or other libraries), and there is no syscall that directly calls the kernel (like Go)..
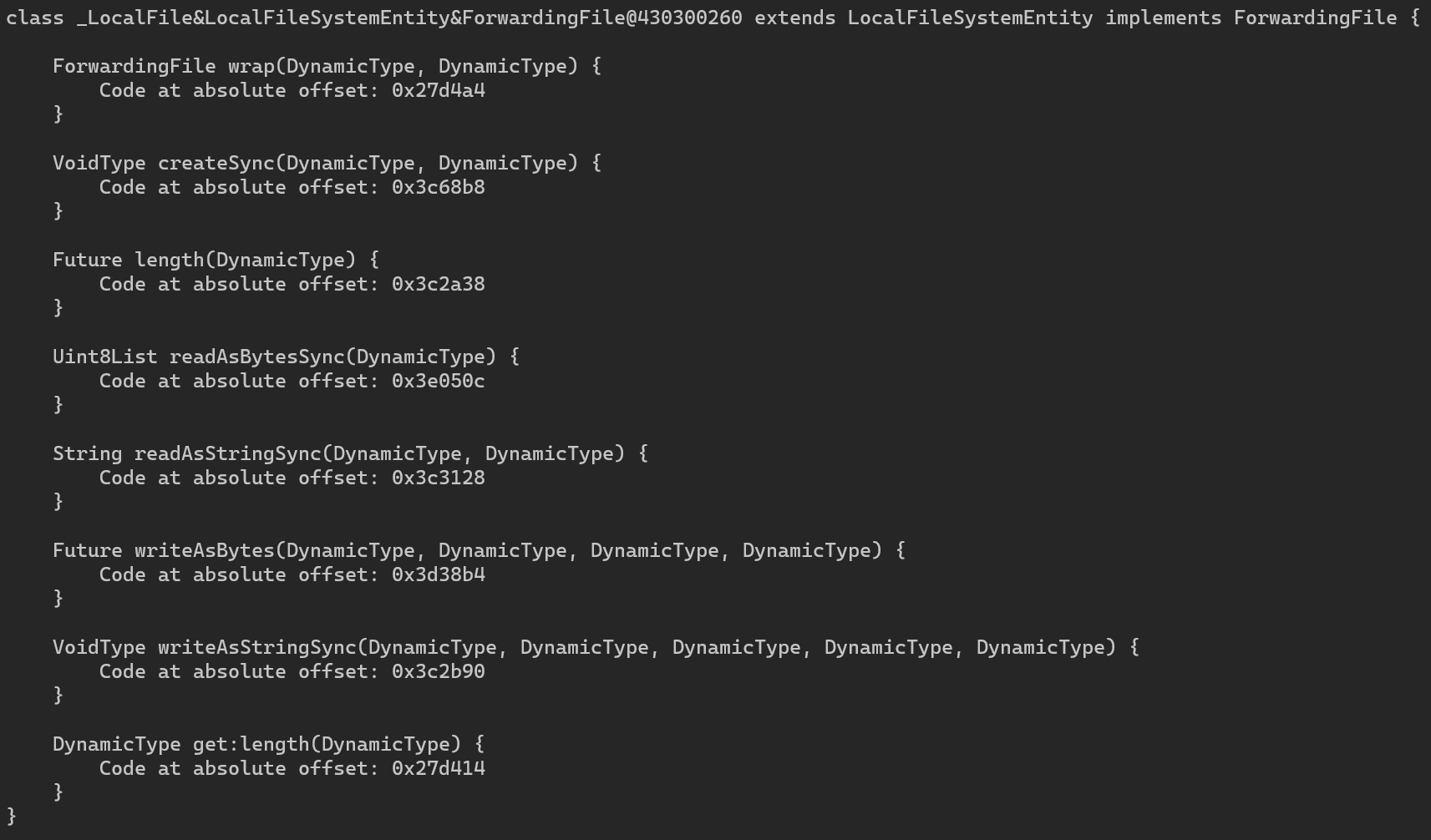
With a tool like Darter dan Doldrums, you can dump the class names and method names, and you can find the address of where the function is implemented. Here is an example of a dump using Doldrums. This helps tremendously in reversing the app. You can also use Frida to hook at these addresses to dump memory or method parameters.
The snapshot format problem
The reason that a specific tool can only dump a specific version of the snapshot is: the snapshot format is not stable, and it is designed to be run by a specific version of the runtime. Unlike some other formats where you can skip unknown or unsupported format, the snapshot format is very unforgiving. If you can’t parse a part, you can parse the next part.
Basically, the snapshot format is something like this: <tag> <data bytes> <tag> <data bytes> … There is no explicit length given for each chunk, and there is no particular format for the header of the tag (so you can’t just do a pattern match and expect to know the start of a chunk). Everything is just numbers. There is no documentation of this snapshot, except for the source code itself.
In fact, there is not even a version number of this format. The format is identified by a snapshot version string. The version string is generated from hashing the source code of snapshot-related files. It is assumed that if the files are changed, then the format is changed. This is true in most cases, but not always (e.g: if you edit a comment, the snapshot version string will change).
My first thought was just to modify Doldrums or Darter to the version that I needed by looking at the diff of Dart sources code. But it turns out that it is not easy: enums are sometimes inserted in the middle (meaning that I need to shift all constants by a number). And dart also uses extensive bit manipulation using C++ template. For example, when I look at Doldums code, I saw something like this:
def decodeTypeBits(value):
return value & 0x7f
I thought I can quickly check this constant in the code (whether it has changed or not in the new version), the type turns out to be not a simple integer.
class ObjectPool : public Object {
using TypeBits = compiler::ObjectPoolBuilderEntry::TypeBits;
}
struct ObjectPoolBuilderEntry {
using TypeBits = BitField<uint8_t, EntryType, 0, 7>;
}
You can see that this Bitfield is implemented as BitField template class. This particular bit is easy to read, but if you see kNextBit, you need to look back at all previous bit definitions. I know it’s not that hard to follow for seasoned C++ developers, but still: to track these changes between versions, you need to do a lot of manual checks.
My conclusion was: I don’t want to maintain the Python code, the next time the app is updated for retesting, they could have used a newer version of Flutter SDK, with another snapshot version. And for the specific work that I am doing: I need to test two apps with two different Flutter versions: one for something that is already released in the app store and some other app that is going to be released.
Rebuilding Flutter Engine
The flutter engine (libflutter.so) is a separate library from libapp.so (the main app logic code), on iOS, this is a separate framework. The idea is very simple:
Download the engine version that we want
Modify it to print Class names, Methods, etc instead of writing our own snapshot parser
Replace the original libflutter.so library with our patched version
Profit
The first step is already difficult: how can we find the corresponding snapshot version? This table from darter helps, but is not updated with the latest version. For other versions, we need to hunt and test if it has matching snapshot numbers. The instruction for recompiling the Flutter engine is here, but there are some hiccups in the compilation and we need to modify the python script for the snapshot version. And also: the Dart internal itself is not that easy to work with.
Most older versions that I tested can’t be compiled correctly. You need to edit the DEPS file to get it to compile. In my case: the diff is small but I need to scour the web to find this. Somehow the specific commit was not available and I need to use a different version. Note: don’t apply this patch blindly, basically check these two things:
If a commit is not available, find nearest one from the release date
If something refers to a _internal you probably should remove the _internal part.
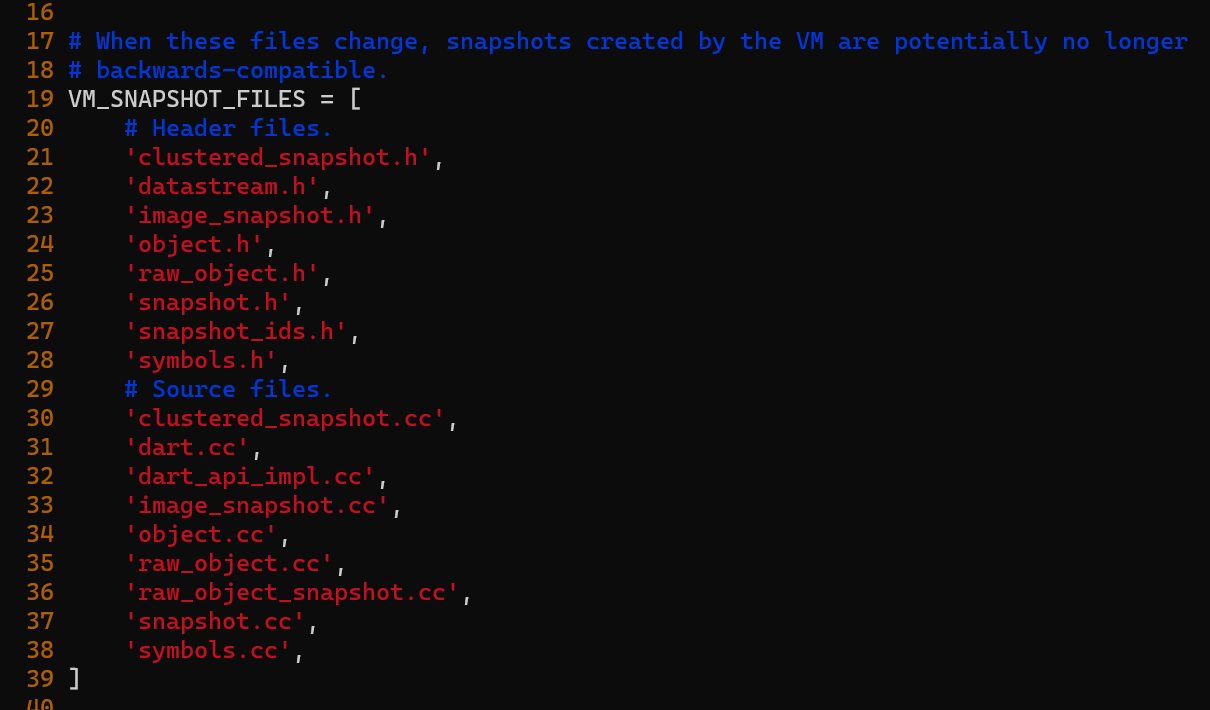
Now we can start editing the snapshot files to learn about how it works. But as mentioned early: if we modify the snapshot file: the snapshot hash will change, so we need to fix that by returning a static version number in third_party/dart/tools/make_version.py. If you touch any of these files in VM_SNAPSHOT_FILES, change the line snapshot_hash = MakeSnapshotHashString() with a static string to your specific version.
What happens if we don’t patch the version? the app won’t start. So after patching (just start by printing a hello world) using OS::PrintErr("Hello World") and recompiling the code, we can test to replace the .so file, and run it.
I made a lot of experiments (such as trying to FORCE_INCLUDE_DISASSEMBLER), so I don’t have a clean modification to share but I can provide some hints of things to modify:
in runtime/vm/clustered_snapshot.cc we can modify Deserializer::ReadProgramSnapshot(ObjectStore* object_store) to print the class table isolate->class_table()->Print()
in runtime/vm/class_table.cc we can modify void ClassTable::Print() to print more informations
Another problem with Flutter app is: it won’t trust a user installed root cert. This a problem for pentesting, and someone made a note on how to patch the binary (either directly or using Frida) to workaround this problem. Quoting TLDR of this blog post:
Flutter uses Dart, which doesn’t use the system CA store
Dart uses a list of CA’s that’s compiled into the application
Dart is not proxy aware on Android, so use ProxyDroid with iptables
By recompiling the Flutter engine, this can be done easily. We just modify the source code as-is (third_party/boringssl/src/ssl/handshake.cc), without needing to find assembly byte patterns in the compiled code.
Obfuscating Flutter
It is possible to obfuscate Flutter/Dart apps using the instructions provided here. This will make reversing to be a bit harder. Note that only the names are obfuscated, there is no advanced control flow obfuscation performed.
Conclusion
I am lazy, and recompiling the flutter engine is the shortcut that I take instead of writing a proper snapshot parser. Of course, others have similar ideas of hacking the runtime engine when reversing other technologies, for example, to reverse engineer an obfuscated PHP script, you can hook eval using a PHP module.
A bricked Xiaomi phone led me to discover a project in Github that uses a MediaTek BootROM exploit that was undocumented. The exploit was found by Xyz, and implemented by Chaosmaster. The initial exploit was already available for quite a while. Since I have managed to revive my phone, I am documenting my journey to revive it and also explains how the exploit works. This exploit allows unsigned code execution, which in turn allows us to read/write any data from our phone.
For professionals: you can just skip to how the BootROM exploit works (spoiler: it is very simple). This guide will try to guide beginners so they can add support for their own phones. I want to show everything but it will violate MediaTek copyright, so I will only snippets of decompilation of the boot ROM.
Bricking my Phone and understanding SP Flash Tool
I like to use Xiaomi phones because it’s relatively cheap, has an easy way to unlock the bootloader, and the phone is easy to find here in Thailand. With an unlocked bootloader, I have never got into an unrecoverable boot loop, because I can usually boot into fastboot mode and just reflash with the original ROM. I usually buy a phone with Qualcomm SOC, but this time I bought Redmi 10X Pro 5G with MediaTek SOC (MT6873 also known as Dimensity 800). But it turns out: you can get bricked without the possibility to enter fastboot mode.
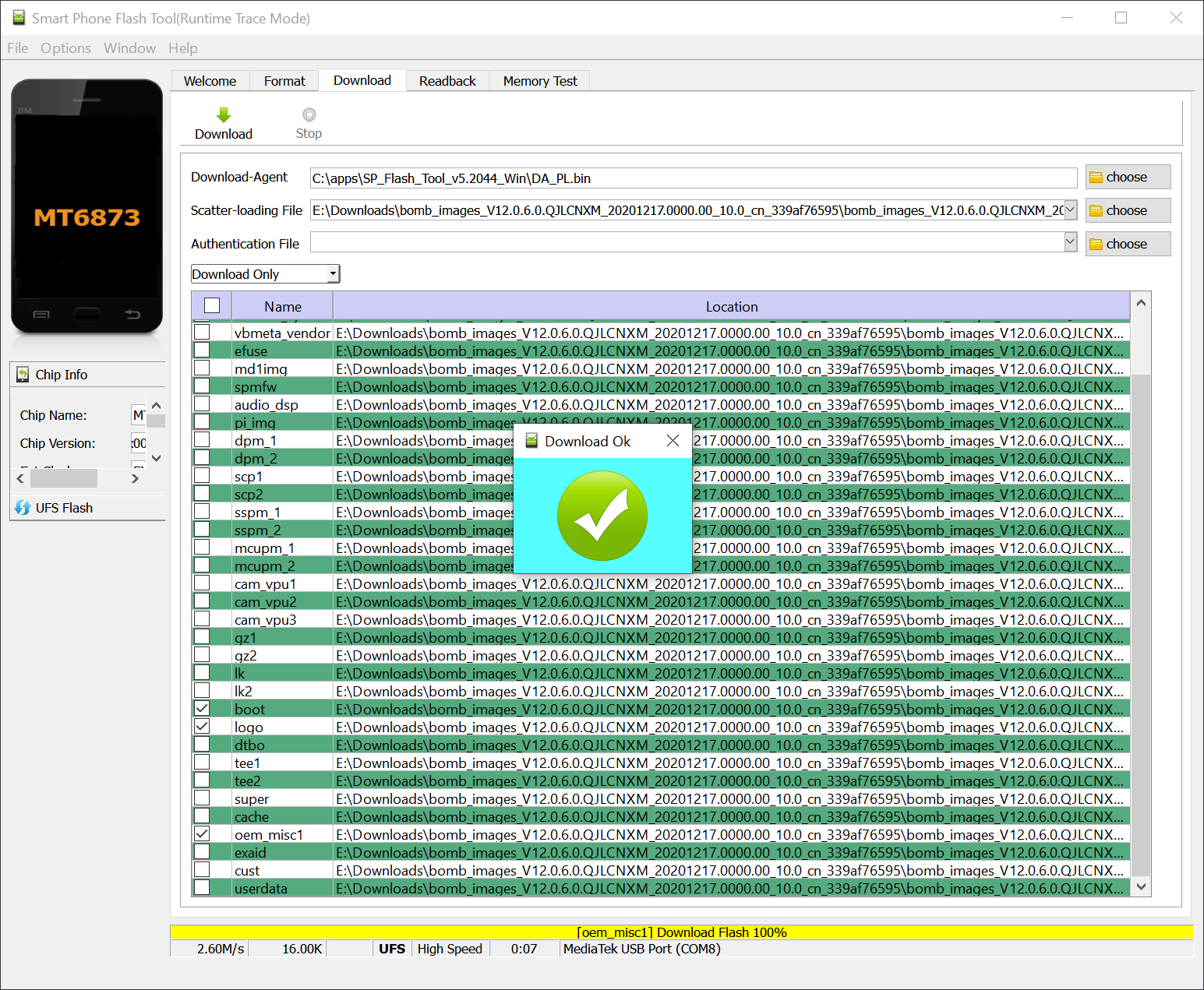
A few years ago, it was easy to reflash a Mediatek phone: enter BROM mode (usually by holding the volume up button and plugging the USB when the phone is off), and use SP Flash Tool to overwrite everything (including boot/recovery partition). It works this way: we enter BROM mode, the SP Flash Tool will upload DA (download agent) to the phone, and SP Flash Tool will communicate with the DA to perform actions (erase flash, format data, write data, etc).
But they have added more security now: when I tried flashing my phone, it displays an authentication dialog. It turns out that this is not your ordinary Mi Account dialog, but you need to be an Authorized Mi Account holder (usually from a service center). It turns out that just flashing a Mediatek phone may enter a boot loop without the possibility of entering fastboot mode. Quoting from an XDA article:
The developers who have been developing for the Redmi Note 8 Pro have found that the device tends to get bricked for a fair few reasons. Some have had their phone bricked when they were flashing to the recovery partition from within the recovery, while others have found that installing a stock ROM through fastboot on an unlocked bootloader also bricks the device
I found one of the ROM modders that had to deal with a shady person on the Internet using remote Team Viewer to revive his phone. He has some explanation about the MTK BootROM security. To summarize: BROM can have SLA (Serial Link Authorization), DAA (Download Agent Authorization), or both. SLA prevents loading DA if we are not authorized. And DA can present another type of authentication. Using custom DA, we can bypass the DA security, assuming we can bypass SLA to allow loading the DA.
When I read those article I decided to give up. I was ready to let go of my data.
MTK Bypass
By a stroke of luck, I found a bypass for various MTK devices was published just two days after I bricked my Phone. Unfortunately: MT6873 is not yet supported. To support a device, you just need to edit one file (device.c), which contains some addresses. Some of these addresses can be found from external sources (such as from the published Linux kernel for that SOC), but most can’t be found without access to the BootROM itself. I tried reading as much as possible about the BROM protocol. Some of the documentation that I found:
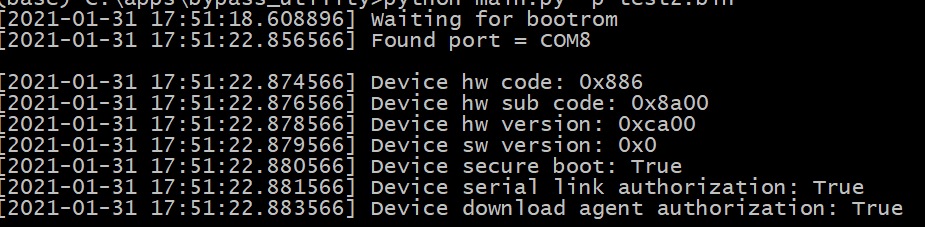
Another luck came in a few days later: Chaosmaster published a generic payload to dump the BootROM. I got lucky: the generic payload works immediately on the first try on my phone and I got my Boot ROM dump. Now we need to figure out what addresses to fill in. At this point, I don’t have another ROM to compare, so I need to be clever in figuring out these addresses. We need to find the following:
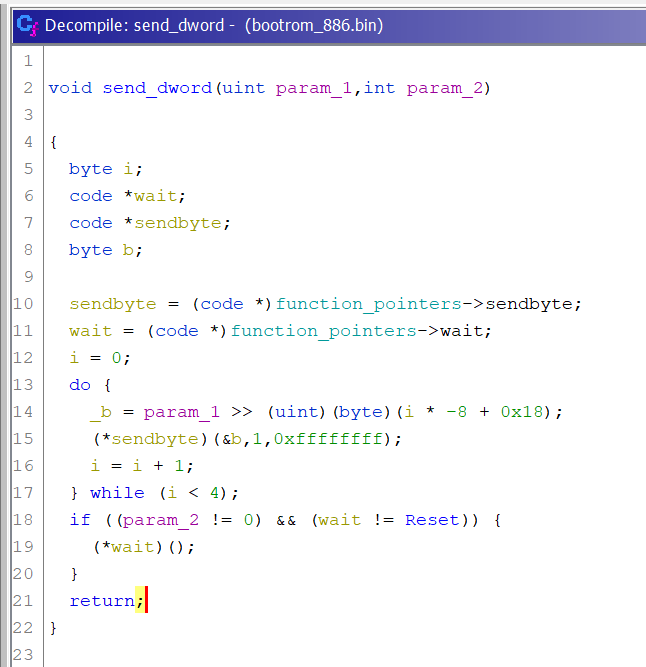
send_usb_response
usbdl_put_dword
usbdl_put_data
usbdl_get_data
uart_reg0
uart_reg1
sla_passed
skip_auth_1
skip_auth_2
From the main file that uses those addresses we can see that:
uart_reg0 and uart_reg1 are required for proper handshake to work. These addresses can be found on public Linux kernel sources.
usbdl_put_dword and usbdl_put_data is used to send data to our computer
usbdl_get_data is used to read data from computer
sla_passed, skip_auth_1 and skip_auth_2, are the main variables that we need to overwrite so we can bypass the authentication
We can start disassembling the firmware that we obtain fro the generic dumper. We need to load this to address 0x0. Not many strings are available to cross-reference so we need to get creative.
Somehow generic_dump_payload can find the address for usb_put_data to send dumped bytes to the Python script. How does it know that? The source for generic_dump_payload is is available in ChaosMaster’s repository. But I didn’t find that information sooner so I just disassembled the file. This is a small binary, so we can reverse engineer it easily using binary ninja. It turns out that it does some pattern matching to find the prolog of the function: 2d e9 f8 4f 80 46 8a 46. Actually, it searches for the second function that has that prolog.
Pattern finder in generic_dump_payload
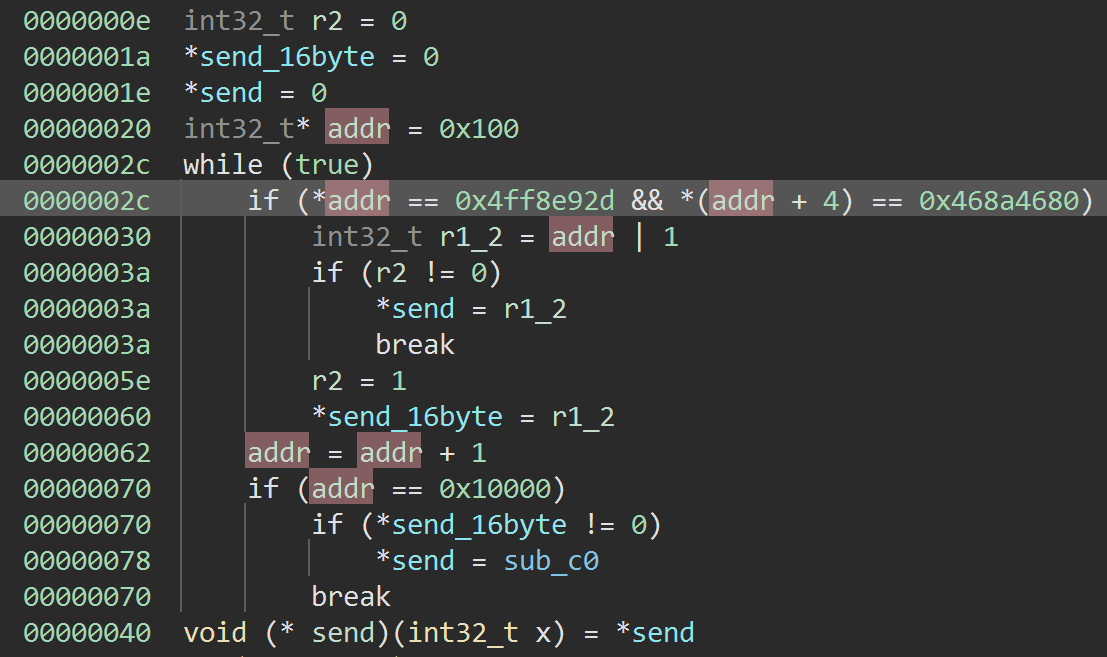
Now that we find the send_word function we can see how sending works. It turns out that it sends a 32-bit value by sending it one byte at a time. Note: I tried continuing with Binary Ninja, but it was not easy to find cross-references to memory addresses on a raw binary, so I switched to Ghidra. After cleaning up the code a bit, it will look something like this:
What generic_dump_payload found
Now we just need to find the reference to function_pointers and we can find the real address for sendbyte. By looking at related functions I was able to find the addresses for: usbdl_put_dword, usbdl_put_data, usbdl_get_data. Note that the exploit can be simplified a bit, by replacing usbdl_put_dword by a call to usbdl_put_data so we get 1 less address to worry about.
The hardest part for me was to find send_usb_response to prevent a timeout. From the main file, I know that it takes 3 numeric parameters (not pointers), and this must be called somewhere before we send data via USB. This narrows it down quite a lot and I can find the correct function.
Now to the global variables: sla_passed, skip_auth_1, and skip_auth_2. When we look at the main exploit in Python, one of the first things that it does is to read the status of the current configuration. This is done by doing a handshake then retrieve the target config.
Target config
There must be a big “switch” statement in the boot ROM that handles all of these commands. We can find the handshake bytes (A0 0A 50 05) to find the reference to the handshake routine (actually found two of them, one for USB and one for UART). From there we can find the reference to the big switch statement.
The handshake
You should be able to find something like this: after handshake it starts to handle commands
And the big switch should be clearly visible.
Switch to handle various commands
Now that we found the switch, we can find the handler for command 0xd8 (get target config). Notice in python, the code is like this:
Notice the bit mask
By looking at the bitmask, we can conclude the name of the functions that construct the value of the config. E.g: we can name the function that sets the secure boot to is bit_is_secure_boot. Knowing this, we can inspect each bit_is_sla and bit_is_daa
we can name the functions from the bit that it sets
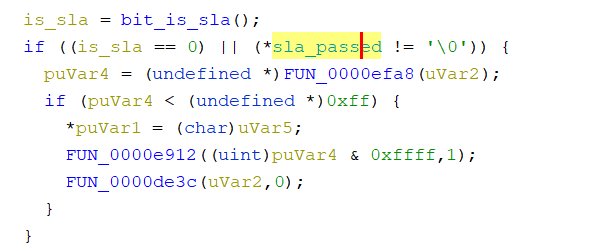
For SLA: we need to find cross-references that call bit_is_sla, and we can see that another variable is always consulted. If SLA is not set, or SLA is already passed, we are allowed to perform the next action.
finding sla_passed
Now we need to find two more variables for passing DAA. Looking at bit_is_daa, we found that at the end of this function, it calls a routine that checks if we have passed it. These are the last two variables that we are looking for.
How the BootROM Exploit Works
The exploit turns out very simple.
We are allowed to upload data to a certain memory space
Basically it something like this: handler_array[value*13]();
But there are actually some problems:
The value for this array is unknown, but we know that most devices will have 0x100a00 as one of the elements
We can brute force the value for USB control transfer to invoke the payload
We may also need to experiment with different addresses (since not all device has 0x100a00 as an element that can be used)
Another payload is also provided to just restart the device. This will make it easy to find the correct address and control value.
Closing Remarks
Although I was very upset when my phone got bricked, the experience in solving this problem has been very exciting. Thank you to Xyz for finding this exploit, and ChaosMaster for implementing it, simplifying it, and also for answering my questions and reviewing this post.